
Sharding: dividir para não quebrar ou: o que o Supabase está tentando fazer com o Postgres
Escalar é fácil até o banco virar o gargalo. O sharding promete resolver isso — porém isso muda tudo.

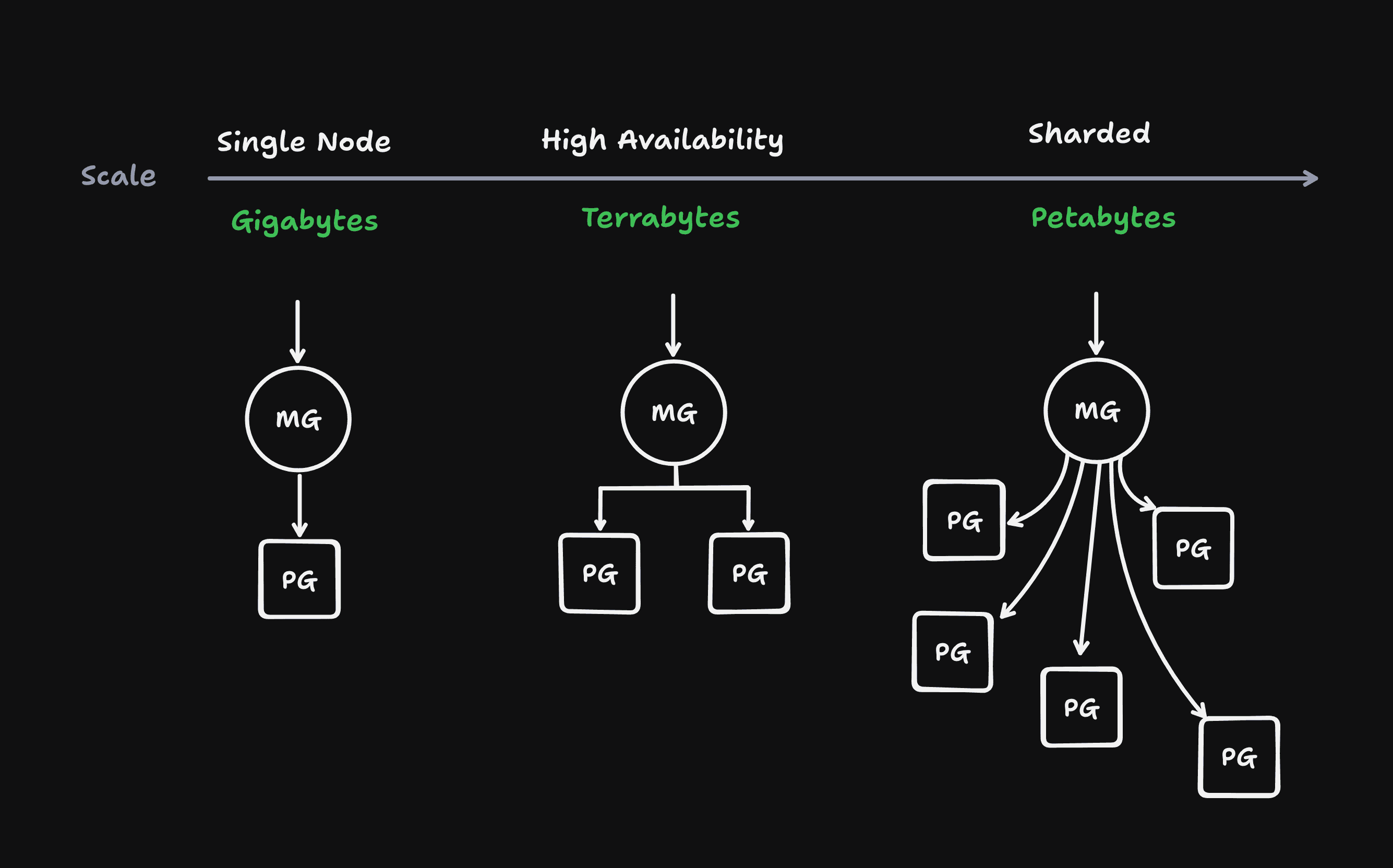
Toda aplicação cresce até o ponto em que o banco de dados se torna um obstáculo.
É o famoso problema bom para o time de produto e CEO, e horripilante para o time de engenharia.
As queries ficam lentas, o cache começa a engasgar, e o plano de “só colocar mais CPU e memória” já não segura o tranco igual antes.
É nesse momento que alguém — geralmente o mais otimista da equipe — solta a frase mágica:
“A gente podia shardear o banco.”
E é aí que começa o problema técnico mais subestimado da engenharia moderna. Quem disse isso não sou eu (apenas), mas o próprio pai do Vitess, Sugu, sistema usado pelo YouTube para escalar MySQL.
O que é sharding (de verdade)
Vamos começar pelo nivelamento: sharding é o simples ato de dividir um banco de dados em partes menores e independentes — os famosos shards.
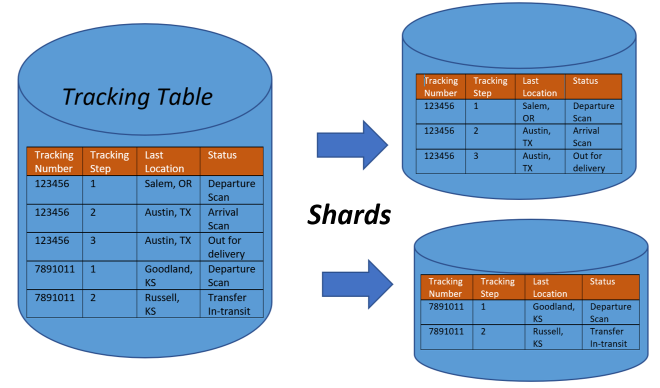
Cada shard guarda uma fração dos dados, e o sistema precisa descobrir onde cada informação vive para fazer consultas (read) ou gravações (write).
É como cortar um dicionário em volumes: de “A a F” num servidor, “G a L” em outro, e assim por diante.
O problema?
Você agora tem dez dicionários que precisam parecer um só.
A promessa é clara: processar em paralelo, aliviar a carga e ganhar escala horizontal.
Mas a realidade é que você também fragmenta sua lógica, seus índices, seus joins e até suas certezas.
O lado feio do sharding
Quando um desenvolvedor fala em sharding com empolgação, geralmente nunca precisou debugar uma query que cruza shards.
Você perde:
Transações globais: commits que envolvem múltiplos shards exigem coordenação distribuída (e latência extra).
Joins complexos: agora o banco precisa buscar dados em lugares diferentes, e o custo explode.
Consistência imediata: o trade-off entre performance e integridade se torna inevitável.
E como se não bastasse, o código da aplicação precisa entender essa topologia.
Você passa a codar com consciência de onde cada dado mora — e isso é o oposto da abstração que um ORM te promete.
Por que todo mundo quer falar de sharding agora
O motivo é simples: o PostgreSQL atingiu ao teto do banco monólito.
Ele é robusto, confiável e maduro — mas nasceu para viver em uma máquina só.
Com o crescimento exponencial das aplicações, o “escala vertical” virou um remendo caro.
E aí entra o Supabase com seu novo projeto: Multigres, uma tentativa de trazer Vitess (a tecnologia que o YouTube usa pra escalar MySQL) para o mundo Postgres.
No papel, a ideia é boa: um proxy na frente do banco que cuida de pooling, roteamento e sharding automático.
Na prática, isso é engenharia de guerra.
Vitess levou anos para amadurecer, e mesmo hoje é usado por poucos times fora de empresas com dezenas de engenheiros de banco.
A promessa do Supabase — e o que ainda está nebuloso
O Supabase diz que o Multigres vai oferecer uma escada de crescimento:
você começa com pooling, depois ganha alta disponibilidade, e só então sharding. Tudo sem mudar seu código.
Mas quem já viveu o pesadelo de integrar shards sabe: não existe “sem mudar o código”.
O roteamento de queries, o schema, os índices e até o modo como você faz migrações — tudo muda.
E quando algo dá errado, debugar um cluster shardeado é como caçar um bug em dez máquinas que juram que estão certas.
Sharding é o tipo de solução que cria seus próprios problemas
Não é que o sharding seja ruim.
Ele é necessário, sim assim como escalar na horizontal.
Mas também é o último estágio nesta subida — aquele ponto em que você troca simplicidade por sobrevida.
A questão não é “se” você vai pagar o preço, mas onde:
no código, na complexidade operacional, ou na latência.
O Supabase está tentando fazer isso de forma mais acessível — e merece crédito por isso.
Mas nenhum proxy mágico vai te livrar da responsabilidade de entender o que significa dividir seu banco em pedaços.